
Forecasting Mathematics
The proof is in the pudding

Yesterday, OpenAI announced that an internal general-purpose reasoning model had disproved the planar unit distance problem, a conjecture Paul Erdős posed in 1946 and reportedly mentioned in lectures for decades. The question asks: among n points in a plane, what’s the maximum number of pairs exactly distance 1 apart? For eighty years, the working assumption was that the answer grew only slightly faster than linear, roughly like a square grid. The model found an infinite family of configurations that do considerably better. To get there, it reached into algebraic number theory, specifically class field towers and Golod-Shafarevich theory. The chain-of-thought runs 125 pages, with the final paper being independently verified.
Fields Medalist Tim Gowers wrote the companion paper:
“If a human had written the paper and submitted it to the Annals of Mathematics and I had been asked for a quick opinion, I would have recommended acceptance without any hesitation.”
OpenAI got this wrong once already. Thomas Bloom, who maintains the Erdős Problems website, called an October 2025 OpenAI claim “a sharp misrepresentation.” Bloom is present alongside this result. Gowers wrote a companion paper. I think the excitement is warranted.
Markets give 79% odds that AI will solve any important mathematical conjecture before January 1st, 2030.

Whether yesterday’s result resolves that market depends on how the creator reads “important” : Erdős Problems are about as prestigious as it gets in combinatorics, and Gowers is saying Annals without hesitation.
First Proof
In February, eleven mathematicians from Harvard, Yale, Stanford, MIT, and EPFL published a challenge they called “First Proof”: ten unpublished research lemmas drawn from their own ongoing work, available to AI systems for one week before the answers were released. None of the problems had appeared in any training dataset and that was seemingly the point.
Without restrictions, GPT-5.2 Pro and Gemini 3.0 Deep Think produced confident proofs for all ten problems. Two held up under expert review. Scientific American ran the headline: “The verdict, it seems, is in: artificial intelligence is not about to replace mathematicians.”
That was February 14th. The Erdős result was announced May 20th.
I don’t think these are actually in tension. First Proof tested whether AI could reliably solve a broad, uncurated sample of research-level problems with no direction, no particular reason to expect the problems to fall within whatever the model is capable of. The Erdős result was a specific, famous, intensively studied problem surrounded by decades of mathematical literature. The model wasn’t working blind: it had encountered every approach anyone had tried across its training data. Producing convincing nonsense across a diverse range of fields is a different failure mode from finding an unexpected connection within a domain saturated with relevant signalling.
Markets give 54% odds that an AI will co-author a mathematics research paper published in a reputable journal before the end of 2026, up 10 points recently.
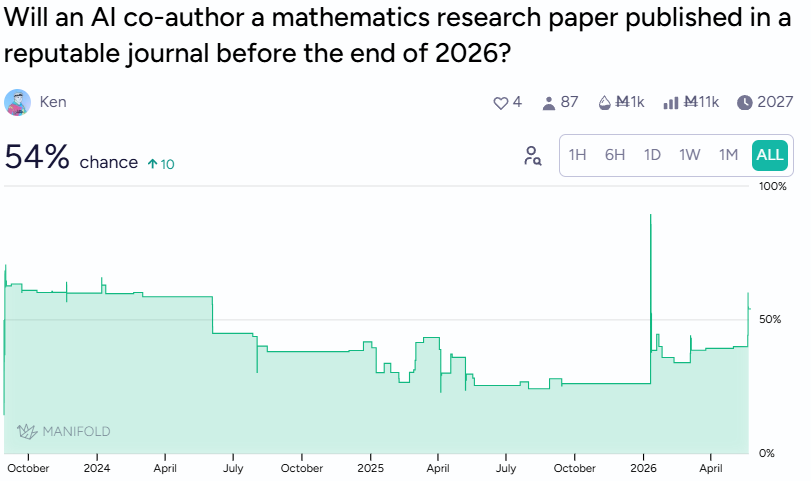
Whether that market is pricing AI capability or academic gatekeeping is rather unclear. I’d also be curious what that market would price if the question specified “without meaningful human scaffolding,” because OpenAI’s First Proof submission involved a weeklong sprint of human-AI collaboration with errors already found in the result. And whether that’s co-authorship or heavily assisted human authorship is a also a question the market hasn’t quite settled.
The First Proof team has announced a second batch of problems. I think this is the more interesting benchmark to watch right now, partly because it’s adversarial in the right way and partly because the second batch will presumably be designed with knowledge of how AI systems approached the first.
The IMO
Markets give 70% odds on a perfect score being achieved by an AI model at the 2026 IMO. I think this is roughly right, maybe slightly generous.

In 2025, both OpenAI and DeepMind achieved gold medals at 35/42. A perfect score is 42/42. Problems 3 and 6 are categorically harder than the rest of the paper. Fewer than 10% of human contestants solve them, and twenty-six humans scored better than either AI last year. The gap between gold and perfect is not a numerical gap. Gold means you solved five of six problems that the world’s best high school mathematicians spent 4.5 hours on. Perfect means you solved them all, including the two that stumped 90% of those students.
The bull case is that DeepMind could train a specialized system specifically targeting IMO 2026, as they did with AlphaProof and AlphaGeometry. Specialized systems have historically outperformed general models on structured competition math by substantial margins. The bear case is that Problems 3 and 6 require genuinely novel proof techniques, closer in character to First Proof than to the kind of structured reasoning current models handle well.
The open-source version sits at 44%. The labs most likely to build a specialized system for IMO 2026 are not the ones who open-source it afterward, and the 24-point gap is roughly the market's price for that constraint.

90 and 19
Two numbers sit oddly against each other in this cluster.
90% on whether AI will produce an Annals-quality paper for $100k by March 2030. Gowers just said he would send the Erdős proof to the Annals without hesitation. This market is up 24 points recently and feels directionally right, perhaps even slightly conservative.

19% on whether AI will outperform humans in all mathematical research areas by 2028,.

I don’t think these are inconsistent, though the gap is real. Producing an Annals-quality paper on a specific famous problem and outperforming human mathematicians as a practice are different things. The Erdős conjecture had been worked on for nearly eighty years - it came preloaded with context, partial results, and a research community that had already significantly narrowed the solution space. Knowing which problems are worth that kind of attention, before anyone else does, is also a significant part of the profession.
As someone who’s yet to have a strong background in mathematics, I lack the ability to truly appreciate the scale of the achievement, but I found Gowers’s comments in the full companion paper to be perhaps the most representative take on where the mathematics community truly stands (among those who haven’t got their heads too far up their own arses to seriously ponder the question).
I find myself not only trying to assess what AI has achieved in this particular case, but also thinking more generally about how such assessments can possibly be made. Can we still identify some mathematical capability that human mathematicians have and AI does not yet have? If so, what might that capability be, and how could one go about demonstrating that AI still lacks it?
Almost certainly the answer to the first question will have to be quantitative rather than qualitative. That is, we are unlikely to be able to show that there is something we can do that current AI models cannot in principle do at all, but we might be able to show that there are things we can still do much more efficiently than those models. But when a model has just solved a major open problem, it is clear that even a modest conclusion like that will not be straightforward to demonstrate, and indeed isn’t obviously true.
I think (for what little my perspective may be worth on assessing a Fields medalist on his carefully selected beliefs on the notion), that this is the right frame of thought. Too often the question gets lost in categorically useless philosophical waffle that sounds profound and gets you precisely nowhere: whether the models are "really thinking," and whether they're "truly creative." None of that matters for working out what they can actually do. What matters is whether they can match or surpass human effort on the same problems, assessed quantitatively. Gowers then goes on to conclude:
In any case, there is no doubt that the solution to the unit-distance problem is a milestone in AI mathematics... Furthermore, even if it is correct that AI cannot yet find a proof that needs a long hint sequence, such proofs are very difficult to find for humans as well, so in the unlikely event that progress in AI mathematics does suddenly stall, we have still probably entered an era where it will become very difficult for humans to compete with AI at solving mathematical problems.
The 19% market is probably best read in this light. It isn’t pricing whether AI will be able to do specific impressive things (as that question is largely settled). But more so an attempt to understand whether the full practice of mathematical research, selection included, gets displaced. Gowers is saying even a stall in AI progress would leave us in an era where human competition with AI on problem-solving is very difficult.
The chess comparison is what most reach for, and there’s a market: 12% on research-level mathematics becoming a sport akin to chess before 2035.

Engines have been superhuman at chess since Deep Blue beat Kasparov in 1997. Chess didn’t die. Players use engines for preparation, opening theory expanded, the quality of human play improved. A 2025 PNAS paper found that AlphaZero’s internal representations contained concepts grandmasters could learn, machine knowledge transferring back to humans quantifiably. Whether mathematics follows the same path is unclear. There’s no Elo rating for being a mathematician, and “akin to chess” probably requires human mathematical practice to reorganise around AI tools the way chess preparation reorganised around engines, which is a higher bar than AI producing messy proofs on famous problems. I’d price 12% a few points higher, but I understand the hesitation.
The market on whether the next Millennium Problem will be solved by an AI lab or a mathematics department has had AI lab as favourite since January.

AI lab sits at 58%, and the small recent uptick looks like an underreaction given the week. The Millennium Problems are a different category from anything above: seven problems, $1 million prize each, one solved in history. Grigori Perelman proved the Poincaré conjecture in 2003 and turned down the million dollars and the Fields Medal. If a model cracks the Riemann Hypothesis, presumably someone will be available to collect.
Happy Forecasting!
- Above the Fold