
Forecasting Gemini
Above the Fold is "Thinking with 3 Pro"

Tuesday morning, the state of the art inched forward again, with the release of DeepMind’s latest offering, heralding in, according to Google, a “new era of intelligence.” As you might imagine, the morning started off with a leak. The leaked benchmark scores showed Gemini 3 leading virtually across the board, causing some traders to suspect some sort of prediction market pump-and-dump scheme.

The scores were in fact real, though. Though the release lacked the fanfare of previous model unveilings, it’s hard to not be a little impressed with the consistent upward pressure on these benchmarks.

That being said, it’s also hard to know how much faith and stock to place on them. Gemini 3 is smarter than 2.5, that much is clear. How would we know if we are seeing diminishing returns on improvements in model intelligence? Or if we are being fooled by selection bias where the benchmarks that progress are highlighted, while those that remain challenging are elided? Andrej Karpathy agrees with the pertinence of these questions:

Luckily, Manifold has precisely this “ensemble of private evals” that Karpathy hints at. For one, there’s a market resolving to a poll of what % of Manifold users believe Gemini 3 to be a “big step forward for AI.” This is mostly useful as a relative measure, but you can see that users were (1) put off by Google’s lack of a spectacle on the morning of their release day, but subsequently (2) impressed by their engagement with the model, causing the market to rise above 50%, from a baseline of around 30-40% for most of the market’s history.

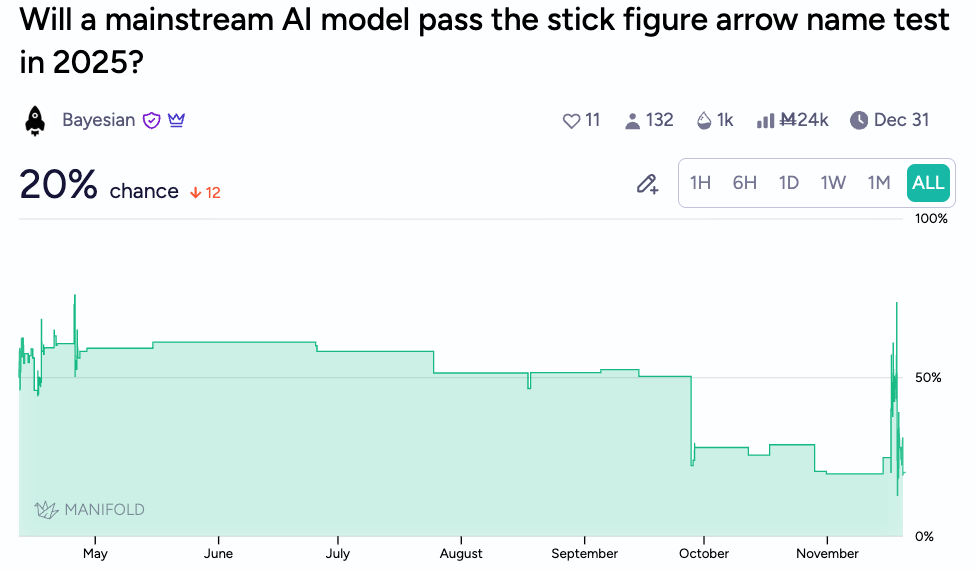
And then there’s stick-figure-arrow-name-bench. A remarkably resistant failure mode in models that can now solve fairly sophisticated spatial reasoning challenges in ARC-AGI-2 is that they fail to follow squiggly lines faithfully.
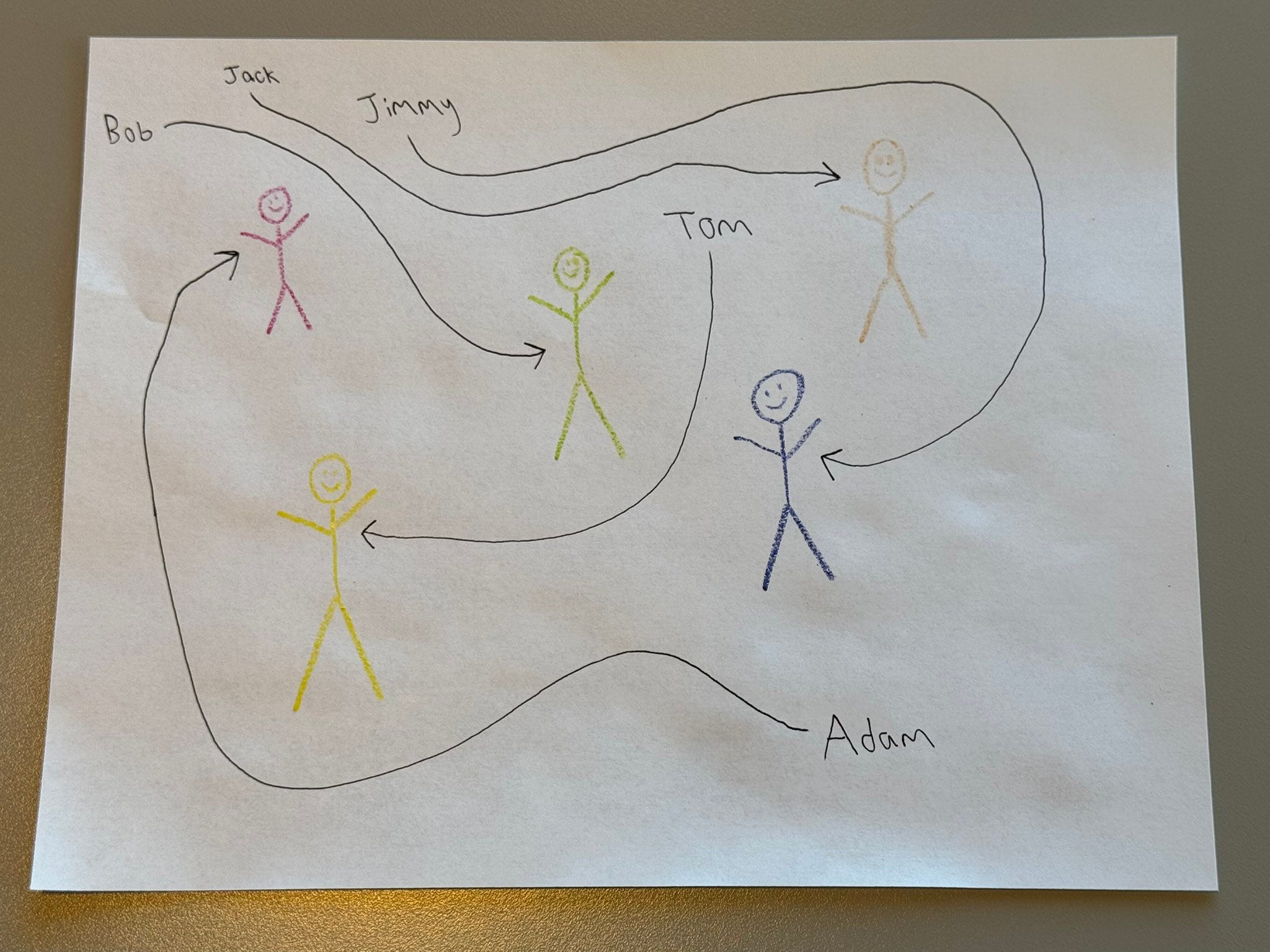
This market jumped up upon reports that a couple users managed to torture the model into getting the answers correct, but the modal response appears to still be failure. That being said, Gemini 3 has done better than its predecessors. It can usually identify Adam, Bob, and Tom as the pink, yellow, and green stick figures, but has trouble with Jack and Jimmy. To be fair, when checking the output, I myself initially switched Jack and Jimmy, so perhaps this is a very human blindspot.
But it’s hard to square these kinds of failures with the saturation of benchmarks for a number of other complex visual reasoning challenges.

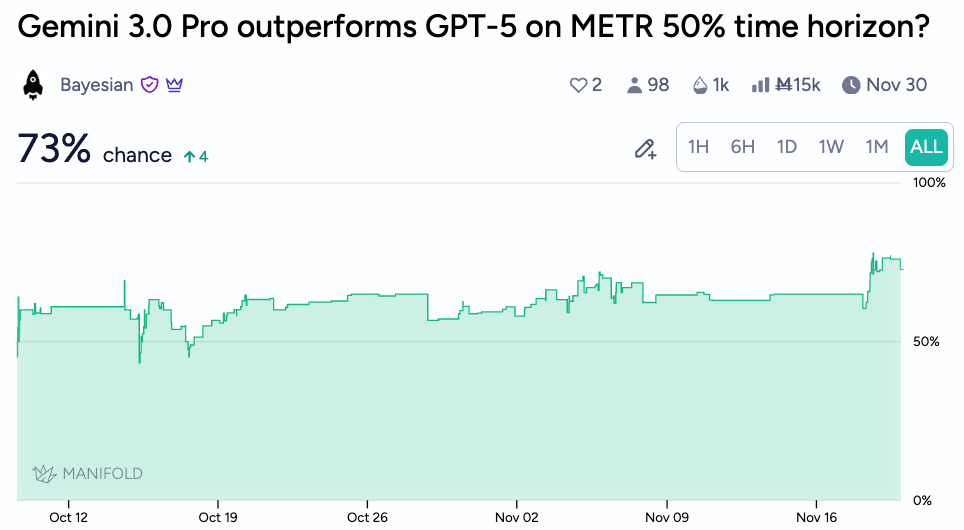
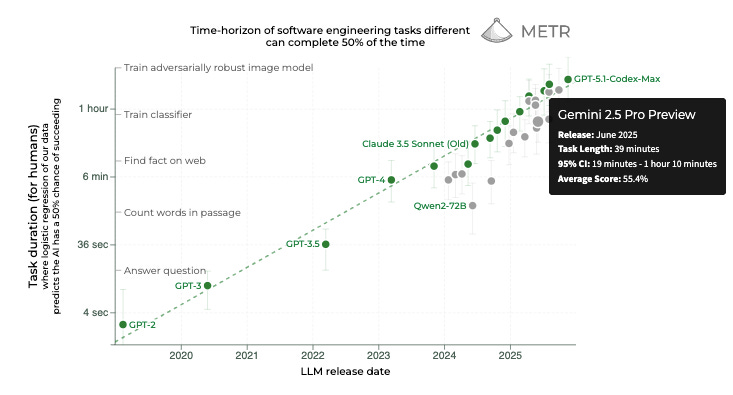
As for high-quality, external benchmarks, I’ve written in past newsletters about Manifold traders tracking METR’s 50% time horizon — a measure of how well an AI system can successfully complete long, complex tasks. Gemini’s models have tended to lag behind OpenAI’s offerings in the past, and GPT-5’s 2hr 15min stands as the score to beat. The market bumped upon release, indicating that Gemini 3 might be outpacing forecasters’ expectations slightly.
Google is also expected to soon announce an upgrade (perhaps today?) to their image generation model, which has been faithfully generating origami crane-featuring Substack preview images for Above the Fold.

Of course, if this does drop today, Manifold may not notice. I expect they’ll be quite busy forecasting how a particular user’s 6-year old daughter will resolve a market:

Happy Forecasting!
-Above the Fold
I can see why AI have blind spots as the stick figure test designer also had one - all the names are male associated names. Are there no women stick figures in AI land?